제 1장 파일의 기본개념
파일(File)

개념적 : 정보의 집합
물리적 : 바이트의 나열
1. 파일의 유형
⑴ 텍스트 파일
일반 문자열이 들어가는 파일이지만, 저장 정보의 해석 방식, 운영 체제와 연결되는 프로그램의 방식에 따라 이진 파일과 구분
사람이 인지할 수 있는 문자열의 집합으로부터 문자열로만 이루어짐
⑵ 이진 파일
컴퓨터 파일로 컴퓨터 저장과 처리 목적을 위해 이진 형식(인코딩된 데이터를 포함)
Ex) hwp, doc, ppt 등 확장자의 컴퓨터 문서 파일
이진 파일에는 그림 및 사진 파일, 동영상 파일, 압축파일 등 다양한 종류
2. 파일의 선별
파일의 식별을 위해 Header와 Footer에 2~4Btye 정도의 고유한 값을 저장 => 시그니처, 매직넘버
윈도우에서 레지스트리에서 파일확장자에 따라 사용할 프로그램을 관리
3. 파일의 상태 정보
파일 이름(File Name)
파일 종류(File Type)
파일 크기(File Size)
파일 생성 시간(Created Time)
최근 파일 접근 시간(Last Accessed Time)
최근 파일 갱신 시간(Modified Time)
소유자(File Owner)
파일 속성(Attributes)
접근 권한(Access Right)
파일 저장 위치(Physical Location)
제 2장 파일의 기반 요소
1. 파일의 구성
데이터는 레코드 형태로 구성, 각 레코드는 연관된 데이터 항목들로 구성
각 항목은 여러 개의 Byte로 구성되며 레코드의 특정 필드에 해당
하나의 파일은 여러 개의 레코드들로 구성되며, 대부분 모든 레코드는 같은 레코드 타입
파일 내의 각 레코드의 크기가 모두 같을 때 = 고정 길이
하나 이상의 필드의 길이가 서로 다르거나, 다중값을 가질 경우 = 가변 길이
2. 블로킹 및 레코드 저장 방식
⑴ 블로킹의 개념
블록 : 디스크와 주기억장치 사이의 데이터 전송단위
한 파일의 레코드들을 디스크 블록들에 할당해야 한다.
B>R :
Bf = B/R(B : 블록의 크기, R : 레코드의 크기, Bf : 블로킹 인수)
각 블록에 저장할 수 있는 레코드의 평균 개수
b = r/Bf(r : 레코드의 수, b : 파일이 필요로 하는 블록의 수
Ex) 레코드의 크기 100Byte, 레코드의 수 10,000개, 블록 크기 1,024Byte일때 블로킹 인수와 필요한 블록들의 갯수는?Bf =B/R이므로 10.24 ≒ 10, b = r/Bf이므로 1,000
⑵ 레코드 저장 방식
비신장 조직 : 레코드들을 디스크 블록들에 저장할 때 레코드가 각 블록의 경계를 넘지 않도록 하는 방식
신장 조직 : 블록이 디스크 상에 인접해 있지 않다면 레코드의 나머지 부분을 저장하고 있는 블록을 가리키는 포인터를 처음블록의 마지막에 두는 방식 (B < R인 경우 사용)
3. 버퍼링의 개념
두 개의 매개 사이에서 충돌을 완화하기 위해 일시적으로 데이터를 기억해 다음 데이터와 원활하게 연결하는 역할을 한다. 디스크에서 검색된 블록(혹은 섹터)들을 주기억장치로 전송할 때 전송 속도를 높이기 위해서 주기억장치 내의 여러 개의 버퍼를 예약하여 사용할 수 있다
하나의 버퍼를 판독하거나 기록하는 동안 CPU는 다른 버퍼 내의 데이터를 처리할 수 있다
이는 CPU 처리와 병렬로 주기억장치와 디스크 간에 데이터 블록을 독립적으로 전송할 수 있기 때문
이중 버퍼링 : 디스크 블록이 주기억장치로 전송되면 CPU는 그 블록에 대한 처리를 하고, 동시에 디스크 I/O 처리기는 다음 블록을 판독하고 다음 버퍼로 전송
이를 사용하면, 첫 번째 블록에 대한 탐구시간과, 회전 시간을 제거할 수 있다
제 3장 파일시스템의 구조
파일 시스템은 운영체제가 사용자들이 생성 및 저장하고 사용하는 이러한 파일들을 관리하고 사용자들로 하여금 보다 쉽게 이러한 작업을 할 수 있도록 지원 및 관리하는 역할을 한다.
1. 논리적 구조
사용자에게 파일 시스템이 어떻게 보이는지에 대한 구조를 말함.
대부분 운영체제는 지정된 파일들을 보관 및 저장할 수 있는 디렉토리(Directory) 또는 폴더(Folder)라는 개념을 지원
⑴ 평면 디렉토리 구조
파일시스템 전체에 하나의 디렉토리만이 존재하고 모든 파일들을 이 하나의 디렉토리에 저장하도록 하는 구조
단점 :
모든 파일들이 한 디렉토리에 존재해야 하므로 이름을 모두 다르게 지정해야함.
다중 사용자 환경의 경우에는 여러 사용자 파일들이 모두 한 디렉토리에 존재해야 하기 때문에 문제 발생.

⑵ 2단계 디렉토리 구조
각 사용자마다 디렉토리를 하나씩 배정하여 자신의 파일들을 저장하고 관리하며, 더 이상의 하부 디렉토리 생성은 불가능

⑶ 계층 디렉토리 구조
사용자들로 하여금 자신의 파일들을 나름대로의 기준으로 분류하여 이를 별도의 디렉토리에 유지할 수 있도록 하고, 한 디렉토리 내에 다른 디렉토리의 생성 및 삭제가 동적으로 이루어질 수 있도록 하는 개념
Windows, MS-DOS 등 대부분의 운영체제에서 사용되는 구조
루트 디렉토리(Root Directory)라는 최상위 디렉토리가 존재하며, 그 하부에 다시 여러개의 디렉토리 또는 파일들이 존재
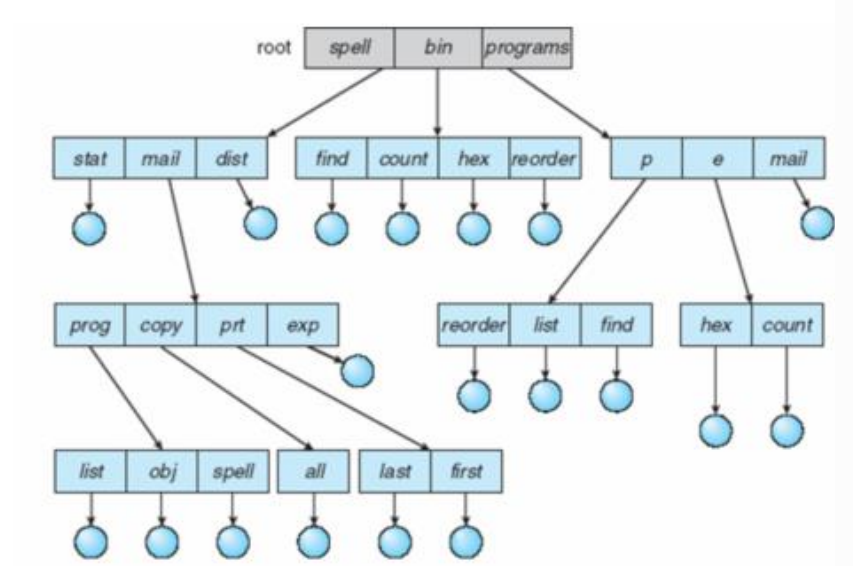
⑷ 비순환 그래프 디렉토리 구조
여러 사용자들이 공유하고자 하는 파일들을 하나의 디렉토리 또는 일부 서브 트리에 저장해서 여러 사용자들이 같이 사용할 수 있도록 지원하기 위한 구조
성능적인 측면에서 비순환 그래프의 공유 부분을 두 번 순회하는 것은 좋지 않다.
설계된 알고리즘은 계속 탐색하고 종료하지 못하는 무한 루프에 빠질 수도 있다.
한 가지 해결책은 한 번에 검색 할 수 있는 디렉토리의 숫자를 임의로 제한하는 것이다.
장점 : 파일을 검색하고 파일에 대한 참조의 존재 여부를 결정하는 알고리즘이 비교적 간단
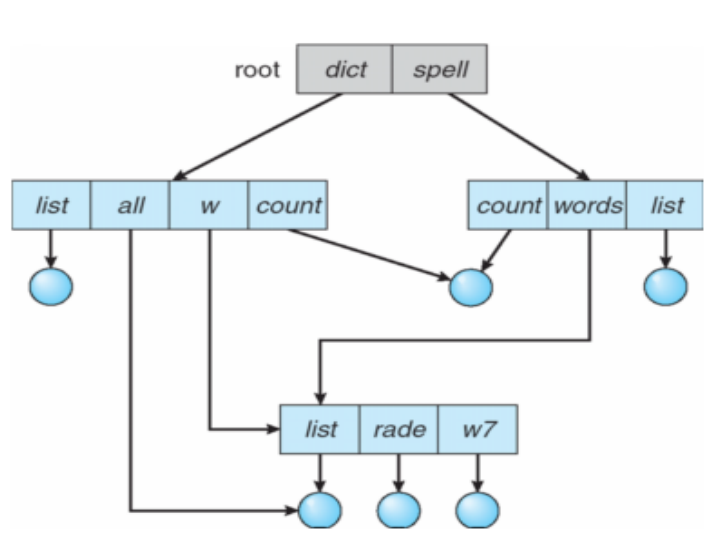
⑸ 일반 그래프 디렉토리 구조
단계 디렉토리부터 시작해서 사용자가 서브 디렉토리를 생성하면 트리 구조가 형성된다.
단순히 새로운 파일이나 디렉토리를 기존의 트리 구조 디렉토리에 추가하는 것은 트리 구조의 성질을 유지하지만 기존의 트리에 새로운 링크를 추가하면 트리 구조는 파괴되고 일반적인 그래프 구조가 될 수 있다.

2. 물리적 구조
- 연속 할당 기법(Contiguous Allocation) : 하나의 파일을 저장하기 위해 필요한 공간을 디스크상의 연속된 블록들에 저장
- 비연속 할당 기법(Discountiguous Allocation) : 디스크상 흩어져 있는 여러 블럭들에 저장.
- 연속 할당기법은 디스크 공간관리의 측면에서 비효율적이기 때문에 일반적으로 비연속 할당 기법을 사용
파일에 대한 디스크 공간의 할당과 관련하여, 어느 파일의 내용이 어느 디스크 블럭들에 할당되어 있는지가 유지되어야 할 것이며, 또한 비어 있는 디스크 블럭들에 대한 정보도 유지되어야 한다.
각 파일에 할당된 디스크 공간, 즉 블럭들을 유지하는 일은 디렉토리나 파일의 상태 정보를 유지하는 부분에서 이뤄진다.
그러나, 디스크 상의 빈공간(Free Space)들을 관리하는 일은 파일시스템 전체적으로 수행되어야 한다.
⑴ 비트 벡터 기법(Bit Vector)
파일시스템 내의 모든 데이터 블록에 대해 각 디스크 블록이 현재 사용중인지 아닌지를 표시하는 1비트의 플래그를 두는 방법 / 비트 백터는 커널(Kernel)의 파일시스템에서 유지하고 관리
⑵ 연결 리스트 기법(Linked List)
디스크 상의 모든 빈 블록을 연결 리스트로 연결하고 이중 첫 번째 빈 블록에 대한 포인터만을 커널에서 유지하도록 하는것
=> 각 빈 블록에는 다음 빈 블록에 대한 포인터를 유지하도록 하는 것
⑶ 그룹화에 의한 기법(Grouping)
각 빈 블럭에서 n개의 빈 블럭 번호들을 유지하도록 한다.
이중 n-1 개의 번호는 빈 블럭들의 번호이며, 나머지 하나의 번호는 다음번 n개 빈 블럭 번호를 갖는 블럭의 번호이다.
즉,이 기법은 위에서 언급한 연결 리스트를 기본적으로 사용하고 있으나 연결 리스트의 각 노드에 n개의 빈 블럭 번호들이 유지된다는 차이점을 갖는다.
따라서 연결 리스트에 연결되는 노드의 수가 위 기법에 비해 약 1/n 정도로 적어지게 될 것이다
⑷ 카운팅에 의한 기법(Counting)
디스크의 빈 공간을 블록 단위로 관리하지 않고 연속된 빈 블록들을 하나로 묶어 관리하는 기법
디스크 공간을 연속 할당하는 시스템에서 유용한 기법
제 4장 파티션(Partition)
1. 파티션의 개념
연속된 저장 공간을 하나 이상의 연속되고 독립된 영역으로 나누어서 사용할 수 있도록 정의한 규약

파티션을 나누기 위해서는 저장장치에 연속된 공간에 있어야 한다.
하나의 하드디스크에는 여러개의 파티션을 나눌 수 있지만, 두 개의 하드디스크를 가지고 하나의 파티션을 만들 순 없다.
파티션의 사용 용도
- 하나의 물리적인 디스크를 여러 논리 영역으로 나누어 관리를 용이하게 한다.
- OS 영역과 Data 영역으로 나누어 OS 영역만 따로 포멧 및 관리를 하기 위해 사용한다.
- 여러 OS를 설치하기 위해 사용한다.
- 하드 디스크의 물리적인 배드 섹터로 특정 영역을 잘라서 사용하기 위해 사용한다.
2. 파티션과 볼륨
볼륨
OS나 Application 등에서 이용할 수 있는 저장 공간, 즉 섹터(Sector)의 집합이다.
연속된 공간이 아니여도 볼륨으로 볼 수 있다.
즉, 2개의 하드디스크를 사용하는 경우 하나의 하드디스크처럼 인식하여 사용할 수 있다.
파티션 역시 저장 공간이기 때문에 볼륨으로 볼 수 있다.
하지만 반드시 연속된 섹터의 집합이여야만 한다.
만약 하나의 파티션에 용량이 부족할 때 볼륨의 개념을 활용하면 2개의 파티션을 1개의 볼륨으로 사용할 수 있겠지만,
그렇지 않다면 파티션은 반드시 연속된 공간을 활용해야 하기 때문에 기존의 파티션 2개를 삭제한 뒤 새로운 파티션을 다시 설치 해야 한다.
3. MBR(Master Boot Record)
⑴ 개념
부팅에 필요한 부트 코드와 각각의 파티션에 대한 정보를 저장하는 파티션 테이블을 저장하는 영역
VBR이 2개 이상으로 구성되었을 때, VBR의 위치 정보를 저장하는 곳
⑵ 구조
디스크의 첫 번째, 즉 0번 섹터에 있는 MBR의 일반적인 구조는 부트코드(Boot Code, 446Byte), 파티션테이블(Partition Table, 64Byte), 시그니처(Signature, 2Byte)로 총 512Byte로 구성되어 있다.
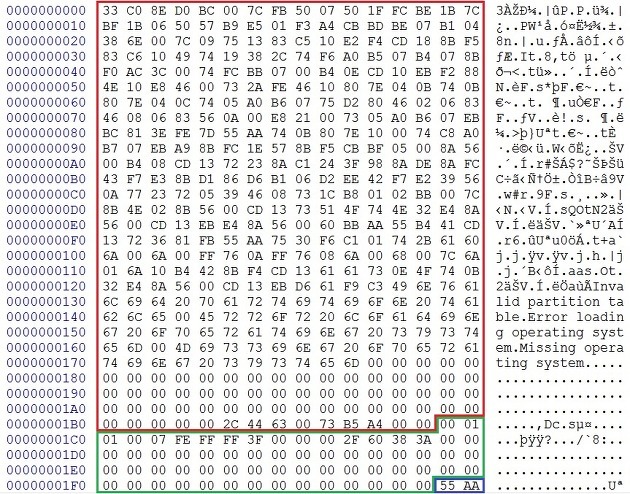
파티션 테이블 영역은 총 64Byte로 16Byte씩 총 4개의 파티션 정보를 표현할 수 있다.


4. 확장 파티션(Extended Partition)
⑴ 개념
MBR 영역의 파티션 테이블에서 4개까지만 파티션이 표현되나, 4개 이상의 파티션 정보를 표현하기 위해서 사용할 수 있다.

⑵ 구조
확장 파티션도 기존 파티션 엔트리와 구조는 동일
확장파티션 엔트리의 LBA Address는 추가 파티션의 시작 주소가 아닌 확장 파티션에 대한 정보가 있는 곳을 저장


Boot Flag : 부팅이 가능한 파티션인지를 구분하기 위한 값이 저장
부팅이 가능하면 0X08의 값을 저장하고 부팅이 불가능하면 0으로 표시함
Starting CHS Address : CHS모드로 표현하며 파티션의 시작주소를 의미
Partition Type : 파티션에 존재하는 파일시스템의 종류를 나타냄
Ending CHS Address : CHS 모드로 표현하는 파티션의 끝 주소를 의미한다.
Starting LBA(Logical Block Address) : LBA 모드로 표현하는 파티션의 시작이다.
Size in Sector : 파티션에서 사용하는 LBA의 총 개수를 의미하는 것으로 해당 파티션의 총 섹터 개수※ LBA 블록 하나당 512Byte
5. GPT(GUID Partition Table)
⑴ 개념
기존 BIOS 기반 동작에서 개선된 EFI(Extensible Firmware Interface)에서 지원하는 파티션 테이블 형식
※ EFI : 기존 BIOS를 대체하는 운영체제와 하드웨어 펌웨어 사이의 새로운 인터페이스 현재는 UEFI로 발전
⑵ 구조
MBT의 단점을 보안한 형태로 파티션 테이블 엔트리 하나의 크기가 128Byte로 확장됨
전체 파티션 테이블 크기는 16,384Byte로 최대 129개의 파티션을 생성 가능

제 5장 파일시스템의 유형

1. FAT 파일시스템
⑴ 소개
파일 할당 테이블로, Microsoft사의 빌 게이츠가 구현
장점 : 가볍고 심플
단점 : 검색 시간이 오래 걸리며, 시간이 지날수록 단편화 현상이 심함. 현상이 누적될 수록 시스템이 느려짐
⑵ 특징
FAT 12
· FAT 파일시스템의 최초의 표준으로 현재 FAT 파일시스템의 기본 구조
· 플로피디스크에 파일을 저장하기 위해 개발되었으며 계층형 디렉터리 구조 지원
FAT 16
· 하드디스크를 지원하기 위한 파일시스템으로 구조는 FAT 12와 유사한 형태
· 클러스터를 표현하는 비트 수가 12개에서 16개로 늘어나 최대 클러스터 개수는 65,535개로 늘어남
VFAT
· 32bit 보호모드에 적합하도록 코드를 재작성하여 성능 향상, 독점 모드 추가 등 기능 향상
· LFNs(Long File Names) 지원하여 최대 255자까지 파일명 작성 가능
FAT 32
· VFAT를 수정하여 클러스터를 표현하는 비트 수를 32개로 늘림, 다만 32bit 중 4bit는 예약 영역으로 사용하지 않아 총 28bit를 이용해 클러스터를 표현
· 최대 볼륨 크기 2TB 지원
exFAT(Extended FAT)
· FAT 32의 한계를 극복하고자 개발
· 고용량의 플래시 메모리 미디어를 위한 파일시스템
· 여유 공간 계산과 파일 삭제 등 전체적인 기능 향상
· 특허 출원 중인 사유 파일시스템
· NTFS 파일시스템이 자료 구조 오버헤드 등의 문제로 적절치 못한 경우, 이전 버전인 FAT 파일 시스템의 파일 크기/ 디렉터리 제약이 문제가 되는 경우에 사용 가능
· 볼륨 크기 : 16EB
· 파일 크기 : 128PB
· UTC 시간표 지원으로 시간 정밀도가 10ms
· 한 디렉터리에 최대 2,796,202개의 파일을 담을 수 있음
⑶ 구조
FAT16과 FAT32의 기본구조는 대부분 비슷함
FAT16과 FAT12는 구조 동일
FAT의 기본 구조는 FAT영역, 데이터 영역으로 나뉜다.
FAT 12/16은 예약된 영역이 1섹터이며 FAT32는 32섹터이다.
1) 예약된 영역(Reserved Area)
FAT32의 예약 영역은 다른 구조와 달리 32섹터를 사용한다

가. 부트섹터(Boot Sector)
FAT 파일시스템의 첫 번째 섹터에 위치
첫 36Byte는 FAT12/16과 FAT32가 같음
이후부터는 저장되는 정보가 다르므로 구조가 다름

FAT12/16, FAT32이 같은 부분
Jump Boot Code : 기본값 0xEB5890으로 부트 코드로 점프하라는 명령어
OEM 이름(ID) : 운영체제 버전별로 생성되는 값이 다름
Bytes Per Sector : 한 섹터 당 바이트 수
Sector Per Cluster : 한 클러스터가 가지는 섹터의 수
Reserved Sector Count : 예약된 영역의 섹터의 크기
Number of FAT Tables : FAT 영역의 개수
Root Directory Entry Count : 루트 디렉터리에 있을 수 있는 최대 파일 개수
Total Sector 16 : 파일시스템에 있는 총 섹터 수를 표시
Media Type : 미디어 유형
FAT Size 16 : FAT 12/16의 FAT영역의 섹터의 수(FAT 32는 0의 값을 가짐)
Sector Per Track : 저장 장치의 트랙 당 섹터 수
Number of Heads : 장치의 헤더 수
Hidden Sectors : 파티션 시작 전 섹터 수
Total Sector 32 : 파일시스템에 있는 총 섹터의 수
FAT32의 구조
FAT Size 32 : FAT영역의 섹터 수
Ext Flags : 여러 개의 FAT 영역을 사용할 경우 설정값을 표시하는 것
File System Version : 파일시스템의 주 버전과 하위 버전 번호
Root Directory Cluster : 루트 디렉터리가 있는 클러스터 위치, 가변적
File System Information : FSINFO 구조체가 있는 섹터 위치
Backup Boot Record : 부트섹터 복사본이 있는 섹터 위치
Reserved : 예약된 공간
Drive Number : BIOS INT 13h 드라이브 번호
Reserv1 : 사용하지 않음
Boot Signature : 확장 부트 시그니처
Volume ID : 볼륨 시리얼 번호
Volume Label : 볼륨 레이블
File System Type : 파일시스템 형식 표시
나. FSINFO(FAT32)
운영체제가 새로운 클러스터를 어디에 할당하는지 설명하는 구조체

2) FAT 영역
FAT 파일시스템에서 가장 중요한 역할을 담당
클러스터의 할당 상태를 판단하고 파일이나 디렉터리 다음에 할당할 클러스터를 찾는데 사용

3) 데이터 영역(Data Area)

가. 디렉터리 엔트리(Directory Entry)
파일시스템에 저장된 각각의 파일과 디렉터리마다 할당된 데이터 구조체
엔트리 크기는 32byte이며 보통 파일 속성, 크기, 클러스터 시작, 날짜, 시간 정보를 포함
이름 8자와 3글자 확장자를 지원
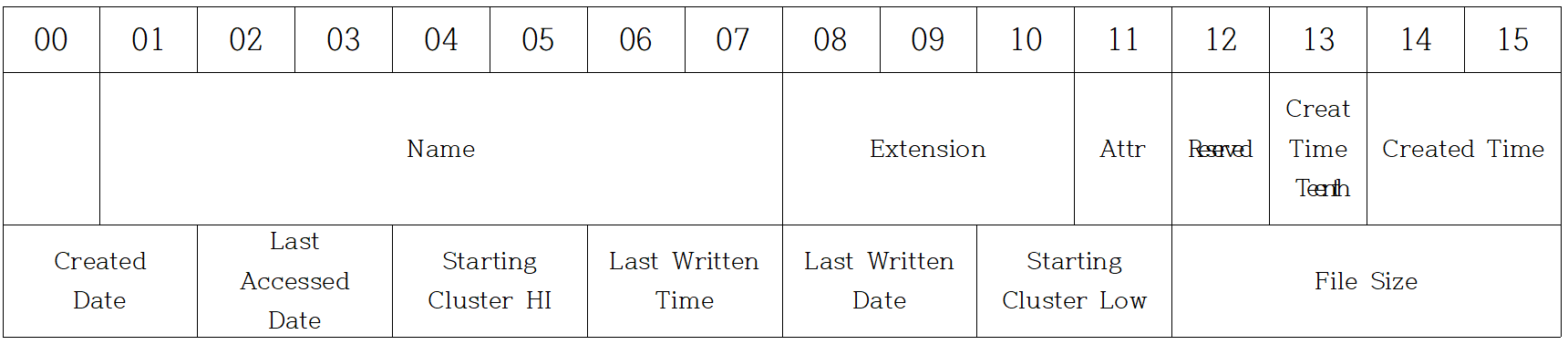
나. 긴 파일명 디렉터리 엔트리(Long File Name Directory Entry)
13문자(Unicode)까지 표현, LFN 엔트리를 14개 사용하여 최대 255문자까지 표현 가능

2. NTFS 파일시스템
⑴ 소개
FAT의 구조상 한계점을 개선하기 위해 개발.
NTFS 또한 OS/2 운영체제에 사용되던 HPFS(High Performance FileSystem)과 매우 비슷한 구조를 가지고 있었고, 실제로 Windows NT의 초기 버전은 HPFS 볼륨과 호환이 되었다.
NTFS 1.0
NTFS 최초 버전으로 Windows 3.1에 포함되었다
NTFS 1.2(NTFS 4.0)
Windows NT 4.0에 포함된 버전으로 NTFS 4.0이라고도 불리며, 가장 널리 쓰이기 시작된 버전
NTFS 3.0(NTFS 5.0)
대부분의 사람들이 NTFS 5.0이라고 부르는 버전으로. Windows 2000에 포함된 버전이다. Windows 2000은 Windows NT 5.0으로 봐도 무관하기 때문에 사람들은 NTFS 5.0이라 불렀으며, 버전이 갑자기 높아진 만큼 많은 기능이 추가되었다. Reparse Point 지원 개선된 보안과 권한 변경 일지(Change Journals)기능 암호화 디스크 쿼터(Disk Quota) 기능 Sparse 파일 지원 디스크 조각 모음 지원 (Windows NT는 조각 모음이 없다.)
NTFS 3.1(NTFS 5.1)
Windows XP와 Windows Server 2003의 운영체제에 포함된 버전으로 NTFS 5.0과 거의 동일하며 호환된다
⑵ NTFS 특징
데이터 복구 기능
데이터의 신뢰성을 높이기 위해 볼륨에 수행하는 모든 작업에 대해 트랜잭션(Transaction) 단위로 기록하며, NTFS는 작업 도중에 어떤 문제가 발생하였을 경우 기록을 조사해 봄으로써 볼륨의 상태를 정상적으로 복구할 수 있다. 저널링 파일 시스템이라고도 함.
암호화
EFS(Encrypting File System)이라 불리며 NTFS 5.0 이후 버전부터 지원
EFS는 인증 받지 않은 다른 사용자들이나 프로그램으로부터 데이터를 보호한다.
NTFS 구조 자체는 암호화하지 않기 때문에 암호화 된 내용은 읽을 수는 있다.
파일 시스템 수준의 암호화 기능이기 때문에 응용프로그램에서 해당 파일이 암호화 되어 있는진 알 수 없다
EFS는 NTFS의 특성으로 간주하진 않고, Windows의 한 기능으로 제공되며 NTFS와 밀접한 관련이 있다.
압축
NTFS의경우 파일시스템 수준의 압축 기능을 제공하며, 압축 알고리즘은 ZIP 파일 포멧으로 유명한 'LZ77'의 변형된 방식을 사용한다.
압축을 할 경우 공간을 절약하는 장점이 있으나, 해당 파일을 읽기/쓰기를 할 때 마다 압축을 풀어야 하기 때문에 성능이 저하된다.
디스크 쿼터
NTFS 5.0이후부터 제공되는 기능으로, 사용자마다 디스크의 사용량을 제한하며, Windows NT는 다수의 사용자들이 하나의 컴퓨터를 쓰는 것을 기본으로 설계하였으나, 여러 가지 이유로 볼륨의 용량을 다 써버린다면 다른 사람들은 더 이상 저장할 수 없게 될 것이다. 이것을 막기 위해 사용자들 마다 할당량을 설정할 수 있다.
Windows에 의존적이기 때문에 해당 볼륨을 구현한 제품에 연결할 경우 제한을 받진 않는다.
ADS(Alternate Data Stream)
NTFS는 다중 데이터 스트림을 지원.
하나의 파일이 하나 이상의 데이터를 담을 수 있다는 의미로, 매우 유용하게 사용됨
파일의 첫 번째 스트림에는 파일의 내용을 담고, 두 번째 스트림에는 파일의 요약정보나 파일의 아이콘 등 여러정보를 담아 둘 수 있다.

FAT에서는 하나의 Data Stream만이 존재하지만 NTFS의 구조에는 Main Stream이 존재
하지만 Main Stream 외에도 여러개의 Data Stream이 존재하는 것을 확인할 수가 있는데, 바로 이것이 Alternate Data Stream인 것이다.
이러한 ADS를 사용하여 데이터를 은닉할 수가 있으며 은닉된 데이터는 일반 사용자가 알아차리기가 힘들기 때문에 악성코드를 넣는 등 악의적인 용도로 사용이 가능하기에 Windows XP 이후에는 이러한 ADS에서 실행파일을 실행되지 않도록 했기에 더이상은 실행파일이 실행되지 않는다.
Sparse 파일
Sparse 파일의 경우 파일의 내용이 대부분 0으로 차있을 경우 해당 파일의 내용을 그대로 볼륨에 저장하지 않고, 그 정보만을 담는 파일의 의미
압축 할 때 이러한 기술이 적절하게 사용되며, 이렇게 되면 디스크에 저장하는 크기를 줄일 수 있음
큰 용량 표현
NTFS의 경우 이론상 Exa Byte(264)까지의 용량을 표현할 수 있으며, 이렇게 큰 값을 위해 64bit를 이용하면 32bit 프로세서에서 성능 저하를 가져 올 수 있으나 NTFS는 용량 표현에 64bit를 사용
이론상 Exa Byte이지만 실제 구현은 (244)까지 처리하도록 되어 있다. 약 16TB 정도
유니코드 지원
NTFS는 다국어를 지원하도록 설계되어 있으며, NTFS에 저장되는 스트링 데이터는 전부 유니코드이기 때문에 다양한 다국어 지원이 가능
⑶ 구조
NTFS의 경우 모든 데이터를 파일 형태로 관리한다.
파일시스템 관리 데이터 들도 파일로 존재하기 때문에 다른 일반 파일들 처럼 볼륨의 어느 위치에 오든지 상관 없으며, 중요한 데이터를 담고 있는 클러스터들이 떨어져 있어도 된다.
매우 구조가 단순해 보이지만 중요 데이터들이 데이터 영역에 들어 있다.

부트레코드(Boot Record)
NTFS의 부트 레코드 구조는 FAT 파일시스템의 부트 레코드와 구조가 비슷하며, 이 영역에는 Windows를 부팅을 위한 기계어 코드와 NTFS 여러 설정 값들이 있다.
이 영역을 분석함으로써 볼륨의 크기, 클러스터의 크기, MFT의 시작 주소의 정보를 얻을 수 있다.
1개의 섹터 뿐이지만, 여러 섹터가 부트레코드용으로 예약되어 있으며, 운영체제가 NTFS를 인식하기 위한 시작점이 되기 때문에 이 영역이 망가지면 인식이 불가능 하다.
NTFS는 부트레코드 영역까지도 파일의 형태로 관리하고 있다고 볼 수 있다. FAT 파일시스템처럼 볼륨을 여러 영역으로 나누어 사용하지 않기 때문에 부트레코드에 존재하는 항목 수가 적은 편이며, FAT 파일 시스템 부트레코드에 비해 내용이 간단하다.
MFT(Master File Table)
볼륨에 존재하는 모든 파일, 디렉토리에 대한 정보를 가진 테이블이다.
NTFS의 가장 중요한 구조체이며, Windows에서 NTFS로 포맷할 경우 Windows는 MFT의 초기 크기를 작게 설정하며 파일이 많아짐에 따라 Windows는 점점 MFT의 크기를 늘려간다.
파일이나 디렉토리가 많아질수록 MFT의 크기는 점점 커지지만 한번 늘어난 MFT는 파일이 줄어든다고 해서 줄어들진 않는다.
파일이 많았던 볼륨에서 많은 파일을 지울 경우 MFT Entry가 많을 것이다.
DATA Area 파일과 디렉터리를 담는 영역으로 FAT 파일시스템과 같이 클러스터 단위로 읽기/쓰기가 이뤄진다.
NTFS는 볼륨의 크기가 크더라도 클러스터 크기를 4096byte로 고정하는데 이는 NTFS 압축기능과 관련됨.
3. UFS 파일시스템
⑴ 소개
Unix 및 Unix 계열 OS에서 널리 사용되는 파일 시스템
Berkeley Fast File System, BSD Fast File System 또는 줄여서 FFS라고 불림
UFS의 초창기 버전은 매우 간단한 구조로 되어 있었다. 이것은 유닉스 초기의 작은 디스크에서는 매우 효율적으로 동작 하였지만, 디스크가 점점 커지면서 성능 저하를 가져 오는 문제가 있었다.
Berkeley의 대학원생이었던 Marshall Kirk McKusick은 실린더를 그룹화하는 기술을 통해 4.2BSD의 FFS를 최적화해 UFS 의 성능을 향상 시켰다 .
⑵ 구조
Solaris 7
Sun Microsystems사는 UFS 에 Logging 기능을 포함시켜 UFS를 Journaling 파일시스템으로 개량하였다.
BSD 4.4 및 BSD계열 Unix
UFS의 구현을 두 계층으로 분할하였다. 상위 계층은 디렉터리 구조와 권한 및 소유와 같은 메타 데이터를 관리하는 계층이고, 하위 계층은 inode 및 실제 데이터를 저장하는 계층으로 사용된다. 이렇게 함으로서 UFS 에 전통적인 FFS(Fast File System)은 물론 LFS (Log-strurctured) 파일시스템까지 다양하게 적용 가능하게 되었다.
Linux
리눅스 역시 다른 유닉스 운영체제와의 바이너리 호환성을 위해 UFS를 지원하지만 이것은 Read동작에 국한된 것으로 UFS에 Writing하는 작업은 완벽하게 지원하지 않는다 (Not provide full support).

부트 블록(Boot Block)
디스크의 가장 처음 저장되는 데이터로 OS의 Bootstrap을 위한 블록이다.
슈퍼 블록(Super Block)
디스크 파일시스템의 식별을 위한 Magic number동 전체 디스크에 대한 정보가 저장된 블록이다.
실린더 그룹(Cylinder Group)
실린더 그룹은 다음과 같은 정보를 포함한다.
- 슈퍼블록의 복제본
슈퍼블록은 매우 중요한 데이터이기 때문에 추후 문제 발생시 복구를 위해 모든 실린더 그룹마다 복사본 을 유지한다.
그룹블록
디스크 통계, free Iist등 각각의 실린더 그룹에 대한 정보를 포함한다.
inode table
각각의 파일에 대한 정보를 저장하고 있다.
이러한 정보에는 파일 위치, 유형, 접근권한 그리고 접근, 수정, 생성 시간에 대한 정보를 포함한다.
⑶ 특징
사용자적 특징
UFS는 계층적 파일시스템이며 완전한 사용자 기반 파일접근 허가 메커니즘을 시용
프로세스 관리와 마찬가지로 시스템상의 각 파일을 특정 사용자에게 소유되며(Owned), 원칙적으로는 해당 사용자 만이 해당 파일에 대한 조작을 수행 할 수 있다.
Root 사용자와 같은 특권이 있는(Priviliged) 사용자는 예외적으로 파일시스템의 모든 파일에 대한 권한을 가진다.
예외적으로 특권이 없는(Unpriviliged) 일반 사용자들이 Super User(Set UID)와 같은 특수 권한을 통해 해당 파일에 접근 할 수 있도록 한다.
구조적 특징
UFS(특히, BSD FFS)는 실린더 그룹(Cylinder group)을 이용하여, 전체적인 파일시스템을 관리
각각의 실린더에는 Book-Keeping information(BKI)를 두고 이를 이용해 실린더를 관리하며, Super Block의 백업본, 사용 가능한 블록 리스트를 나타내는 BitMap(Free List) , 할당된 lnode 개수 동의 정보를 포함한다.
실린더 그룹은 파일 시스템의 기본 단위가 되며 디스크 할당의 경우는 4Kbytes의 블록을 사용하지만, 실제 사용단위는 block보다 작은 fragment를 도입하여 fragment 단위로 할당 받을 수 있게 하였고, 이에 더하여 할당에 제약을 가함으로써 성능이 떨어지지 않도록 하였다.
실린더 그룹을 이용한 파일시스템은 다음과 같은 특징을 갖는다.
- 하나의 파일에 데이터 블럭들이 분산되는 정도가 줄어든다.
실린더 그룹을 사용하더라도 파일들의 fragment는 여전하겠지만, 이전의 유닉스 파일시스템에서 발생하는 심각한 scattermg현상은 나타나지 않을 것이다.
이는 파일시스템이 디렉터리와 그에 속한 파일들을 통일 실린더 그룹 내에 할당하여 주기 때문이다. 즉, 같은 디렉터리에 있는 파일은 같은 실린더 그룹으로, 같은 파일과 연관된 데이터 블럭도 같은 실린더 그룹으로 최대한 할당되도록 한다.
파일 탐구 시간(seek time) 향상
디렉터리와 파이들이 최대한 같은 실린더 그룹에 할당 되도록 하기 때문에 한 파일의 데이터 블록을 찾을 때 최악의 경우라도 16개 이상의 실린더를 넘지 않는다.
큰 파일의 실린더 그룹 독점 방지
큰 파일들이 할당될 때 실린더 그룹 당 2Mbyte를 할당하며 여러 실린더 그룹에 분산되게 된다.
이는 긴 seek 후에야 단지 2Mbyte씩을 read/write를 할 수 있 게 되는 단점이 생긴다.
이를 해결하기 위해 클러스터링(clustering) 기법을 추가하여 큰 파일에 대한 읽기와 쓰기를 순차적(sequentially) 하도록 한다.
4. EXT 파일시스템
⑴ 소개
리눅스를 지원하는 최초의 파일시스템은 Minix 파일시스템 이었지만 여러문제로 인해 리눅스를 위한 Extended File System(ext)을 개발하게 되었다.
Remy Card가 설계한 첫 번째 ext는 1992년 4월에 리녹스에 채택
Ext 파일시스템은 0.96c 커널에 구현된 VFS(Virtual File System) 스위치를 최초로 사용하였으며, 최대 2GB 크기의 파일시스템을 지원하였다.
이후, ext의 성능, 확장성 및 신뢰성 등을 향상시키기 위해 ext2, ext3, ext4 등이 개발되었다.
Ext2
Remy Card에 의해 개발되어 1993년 1월에 발표되었으며, 데비안, 레드햇 등 다양한 리녹스 배포판의 파일시스템으로 사용.
Ext2 에서는 지원되는 파일시스템 크기가 2TB로 확장 되었으며 2.6 커널에서는 Ext2 파일시스템 크기가 32TB 로 확장
Ext3
예기치 않게 시스템이 중단될 때 파일시스템의 신뢰 성을 높여주는 저널링 개념을 도입.
커널 2.4.15 버전에서 처음으로 모습을 드러냄.
Ext2와 호환성을 제공하여 Ext2에서 자료 삭제 및 손실 없이 Ext3로 변경할 수 있으며 저널링을 지원
Ext4
1EB(exabyte) 의 파일시스템을 지원
리녹스 커널 버전 2.6.19부터 Ext4가 포함 안드로이드에서도 사용.
저널링 파일시스템 쓰기 명령이 수행될 때 메인 파일시스템에 업데이트 하기 전에 미리 지정된 저널에 메타 데이터 또는 파일 컨텐츠를 기록하여, 파일 읽거나 쓰는 과정에서 전원이 꺼지거나 시스템 패념 상태가 되었을 때 복구하기 쉽도록 한다.
⑵ 구조

1) 블록 그룹(Block Group)
하나의 블록 그룹은 여러 개의 블록들의 집합체
하나의 블록 그룹에는 파일 시스템의 전체적인 정보를 저장하는 슈퍼 블록(Super Block)과 그룹 디스크립터 테이블(Group Descriptor Table), 그 밖에 아이노드 비트맵(Inode Bitmap), 아이노드 테이블(Inode Table), 파일 데이터 블록(File Data Block)들로 구성
※ 디스크립터 사본 리눅스 혹은 유닉스 계열의 시스템에서 프로세스(process)가 파일(file)을 다룰 때 사용하는 개념으로, 프로세스에서 특정 파일에 접근할 때 사용하는 추상적인 값이다. 파일 디스크럽터는 일반적으로 0이 아닌 정수값을 갖는다.
2) 슈퍼 블록(Super Block)
가장 첫번째 1개 블록에 위치하며 파일시스템의 크기와 환경 설정값 등 파일시스템의 전체적인 정보를 저장
블록 그룹의 시작부터 1024Btyes내에 기록되어야 하고 그 크기로 저장된다.
전체 블록의 갯수, 블록 그룹의 갯수, 각 블록 그룹당 블록의 갯수, 아이노드 테이블 크기 및 블록 그룹당 아이노드 테이블 갯수를 저장

3) 그룹 디스크립터 테이블(Group Descriptor Table)
각 블록 그룹의 정보를 저장한 그룹 디스크립터가 모여있는 구조체
파일시스템 전체의 블록 그룹에 대한 정보를 가지고 있어 매우 중요
슈퍼 블록과 함께 모든 블록 그룹에 동일하게 중복 기록되는 특징


4) 블록 비트맵(Block Bitmap)
그룹 디스크립터 테이블의 크기가 정해진 것이 아니므로 블록 비트맵의 위치도 정해진 것이 아니다.
대신 그룹 디스크립터에 블록 비트맵의 주소가 저장되어 있다.
블록 사용현황을 리틀 엔디안 방식으로 표현하는데 1블록을 1bit로 표현

5) 아이노드 테이블(Inode Table)
아이노드란 파일 시스템에 저장된 모든 파일 혹은 디렉터리에 대한 메타 데이터를 저장하는 구조체
저장되는 데이터는 해당 파일의 크기, 수정, 접근, 속성변경, 삭제 등의 시간 정보를 비롯하여 피일 크기, 파일 모드와 접근 권한, 파일을 저장하는데 필요한 블록의 수 등의 정보가 있다.

I_Block[12]부터는 간접 포인터로 파일 블록을 직접 가리키는 것이 아니라 파일 블록을 가리키고 있는 위치 블록을 중간에 두고 이를 거쳐서 가리킨다.
블록 크기가 4KB일 경우 표현 가능한 최대 파일의 크기는 4MB이다.

I_Block[13]은 위치 블록을 두 번 거치는 형태로 이중 간접 포인터를 사용한다.
블록 크기가 4KB일 경우 최대 파일 크기는 4GB이다.

I_Block[14]은 위치 블록을 세번 가리키는 형태인 삼중 간접 포인터를 사용한다.
블록 크기가 4KB라면, 4TB가 되지만, 실제로 리눅스 커널 내부의 파일 관련 함수들이 사용하는 인자들이 32bit로 구현되어 있어서 최대 표현 가능한 크기는 4GB가 된다.

6) 데이터 블록(Data Blocks)

디렉터리 엔트리(Directory Entry)와 실제 데이터 내용이 저장되는 블록
저장되는 데이터의 양에 따라 블록의 수는 가변적
⑶ Ext4의 특징
하위 호환성 : ext4는 이전 버전 ext3와 상호 호환성을 제공하여 사용가능하다.
시간 소인 정밀도 및 범위 향상 : ext4 이전 버전에서는 초 단위의 시간 소인을 사용하였으나, 프로세서의 속도가 빨라지면서 한계가 드러남. Ext4로 오면서 나노초 (ns) LSB로 확장되어 후속 버전과 호환성을 보장함.
파일 시스템 확장 : ext3에 비해 ext4는 파일 시스템 볼륨, 파일 크기 및 서브디렉토리 제한에 대한 지원이 향상됨. 최대 1EB 파일시스템을 지원함. 파일 1개당 최대 16TB까지 지원. 서브디렉토리 제한이 32KB에서 거의 무한대로 확장됨.
익스텐트(Extent) : Ext3의 메커니즘을 익스텐트로 대체하여 연속되는 블록 시퀀스를 나타냈다.
※ 익스텐트란 EXT3에서 쓰이던 전통적인 블록 매핑방식을 대체하기 위한 것으로 인접한 물리적 블록의 묶음
빠른 탐색 가능 파일 레벨 사전 할당 : Ext4에서는 지정된 크기의 파일을 사전 할당 및 초기화하는 새로운 시스템 호출을 통 해 구현함. 필요한 데이터를 기록한 후 데이터에 대한 제한적인 읽기 성능을 제공할 수 있다.
블록 할당 지연 : 파일 크기를 기반으로 최적화하는 방법으로, 블록을 디스크에 강제로 기록할 때까지 디스크의 물리적 블록을 할당하지 않고 기다린다. 이에 따라 더 많은 블록을 연속 블록에 할당 및 기록할 수 있게 된다. 이 방법은 파일시스템에서 작업이 자동으로 수행 된다는 점을 제외하면 지속적인 사전 할당과 유사하다. 하지만 파일 크기가 미리 알려져 있는 경우에는 지속적인 사전 할당이 가장 효과적인 방법이다.
멀티 블록 할당 : Ext3에서 블록 할당자는 한 번에 하나의 블록을 할당하는 방식으로 동작하였다. 여러 개의 블록이 필요한 경우, 연속 데이터를 연속되지 않은 블록에서 찾을 수 있었다. Ext4 에서는 디스크에 연속되어 있을 수 있도록 여러 블록을 동시에 할당하는 블록 할당자를 사용하여 이 문제를 해결. 또한, Ext3 의 경우에 는 블록 할당을 수행하기 위해 블록마다 한 번의 호출이 필요했지만, 여러 블록을 통시에 할당하는 경우에는 블록 할당자에 대한 호출 횟수가 많이 줄어들기 때문에 할당 속도가 빨라지고 필요한 처리 리소스의 양도 줄어 든다.
파일시스템 저널에 대한 체크섬 검사 : Ext4에서는 저널에 대한 체크섬 기능을 구현하여 올바른 변경 사항만 기본 파일시스템에 적용되도록 보장한다.
온라인 조각 모음 : 파일시스템 및 개별 파일에 대한 조각 모음을 수행하는 온라인 조각 모음 도구를 제공.
'디지털 포렌식 2급 자격증 필기 > 파일시스템과 운영체제' 카테고리의 다른 글
| Windows 시스템 폴더와 레지스터 (0) | 2023.09.14 |
|---|---|
| 운영체제-1 (0) | 2023.09.13 |

댓글